Desde hace ya un tiempo que vamos hablando sobre #Data-Streaming, publicando casos reales como el de ING Direct.
Aunque hoy queremos hacer una “review” general para ir enfocando próximos capítulos ya que, más que nunca, está de “moda” el tener Real-Time en nuestras plataformas de analítica. Por ejemplo en el caso anterior, del Banco ING, podemos ver como las transacciones online que están realizando sus clientes, rápidamente, están disponibles para sus equipos de Customer Support, vital para una eficiente atención al cliente. Ya que en el mismo momento de la transacción, operación, etc… podemos ponernos en contacto con ellos; sea mediante el chat, teléfono, etc… y ellos podrán darnos soporte ya que tendrán disponible nuestras operativas.
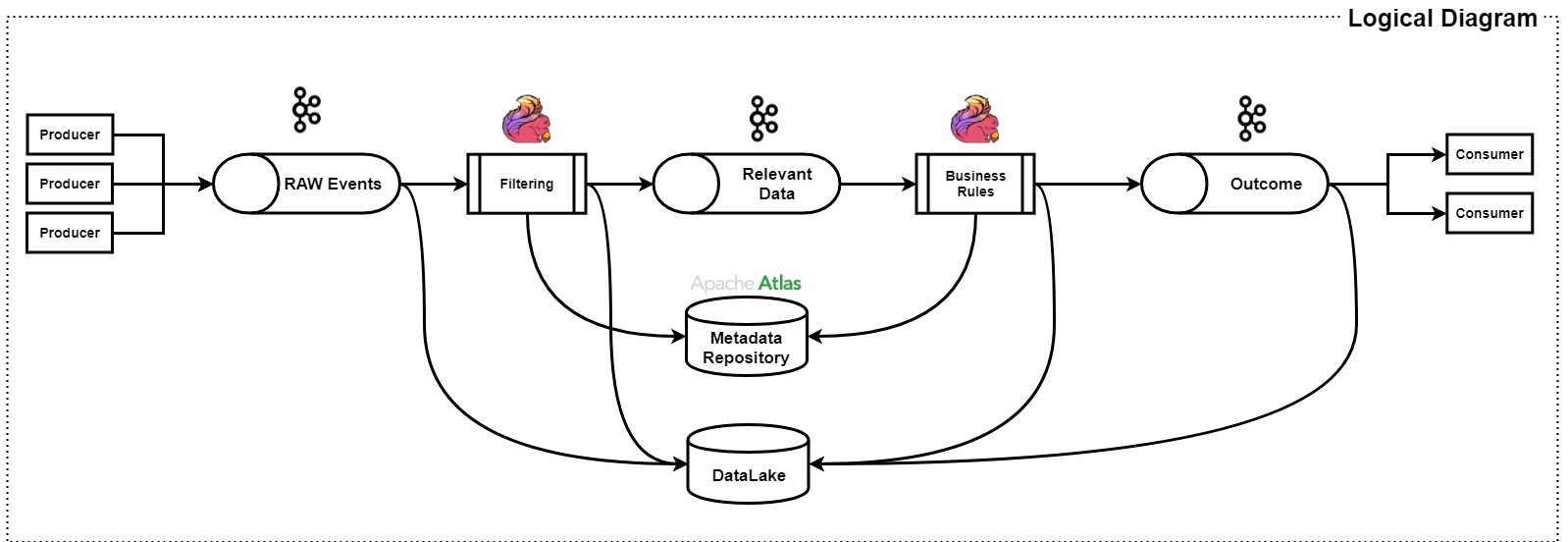
Para ello, hay un interesante sistema de transformación de la información, veamos el siguiente diagrama:
Observamos que, por ejemplo nosotros mismos, podemos ser un “Producer” de datos (transacciones, cambios de divisas, pagos con tarjeta, etc…) y, éstos mismos, son introducidos hacia una “Pipeline” que se asemeja y mucho a un sistema digestivo. Paso a paso se va dando forma al dato para que, un sistema analítico por ejemplo, pueda sacar valor de nuestra información. Para ello observamos dos importantes pasos: “RAW events” y “Outcome”.
El primero, “RAW events”, es tal cual los datos que nosotros mismos hemos generado, no han sido estudiados, ni categorizados, etc… en el segundo caso, “Outcome”, ya serían los datos transformados, es decir: tienen sentido para los sistemas analíticos o de Customer Support, por ejemplo. Para ello podemos utilizar Apache Flink o Spark Sreams para aplicar filtros, reglas, etc… a nuestros datos y que un dato de entrada pueda tener dos salidas, el RAW (el mismo dato) o el dato ya transformado.
Cierto es que, el diagram anterior es una arquitectura totalmente nativa de #Data-Streaming, pero podríamos tener el caso que, nuestra infraestructura no pueda serlo al completo. Es por ello que, también hemos hablado anteriormente de Apache NiFi, que podría “solucionarnos” un poco el problema. Veamos:
En el anterior diagrama tenemos un ejemplo de transformación a #Data-Streaming, es decir, de una arquitectura no nativa a un sucedáneo. Gracias a Apache NiFi podremos hacerlo. En éste caso presentamos una Pipeline que recoge los datos y, mediante procesos de Apache NiFi los introduce a Druid que proporcionará a nuestro proceso rápidas consultas analíticas y en alta concurrencia, para poder potenciar interfaces de usuario interactivas (por ejemplo: cubos).
Libro recomendación
La recomendación de hoy es el libro de Andrew Psaltis: “Streaming Data: Understanding the Real-Time Pipeline”, quien nos dará un más que interesante paseo por Spark, Storm, Kafka, Impala, RabbitMQ, etc….
NOTA: Recuerda que si pulsas en el enlace del libro, me gano una pequeña comisión sin que a ti te cueste nada extra y me estarás ayudando con los costes de mantenimiento del Blog.