De Apache NiFi hemos hablado mucho, mucho, mucho… pero nunca es suficiente. Es una de las grandes soluciones a nuestros males y hoy, haremos un resúmen de lo más destacado.
Antes que nada, te recomiendo que leas el libro “Advanced Data Streaming with Apache NiFi: Engineering Real-Time Data Pipelines for Professionals”, el cual es un libro muy recomendado para continuar profundizando en el tema. Ahora, empecemos nuestro recorrido por la herramienta:
Apache Nifi multiple processor
Una de las ventajas de Apache NiFi es que dispone de múltiples procesadores para tratar flujos de información. Por ejemplo:
- JSON: SplitJson, EvaluateJsonPath, ConvertJSONToAvro
- AVRO: SplitAvro, ExtractAvroMetadata, ConvertAvroToJSON
- TEXT: SplitText, ExtractText, RouteText
Pero, tenemos una série de procesadores que, símplemente, son mágicos como:
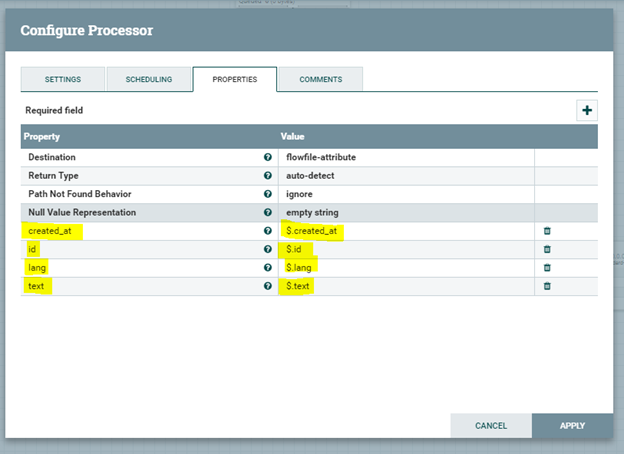
- EvaluateJsonPath, que va a permitir poder recorrer un JSON en búsqueda de valores y, categorizarlos. Un claro ejemplo es la siguien imágen, que a partir del retorno de la API de Twitter podemos categorizar datos como: “id”, “lang”, “text”,etc… En un siguien proceso podremos aplicar “Rules” a lo que acabamos de categorizar.
Apache NiFi Record Processing (Record-Oriented)
Otro de los puntos fuertes de Apache NiFi es que la estructura es agnóstica a los datos. No le importa qué tipo de datos está procesando. Hay múltiples procesadores, como decíamos, para trabajar con JSON, XML, CSV, Avro, imágenes y vídeo, etc… Apache NiFi en una poderosa herramienta para extraer datos de fuentes externas; enrutar, transformar y agregar datos; y finalmente entregarlos a sus destinos finales.
En las versiones más recientes de Apache NiFi, a partir de la 1.2.0, se añadió la capacidad “Record-Oriented”, para poder trabajar con datos orientados a registros. Los nuevos procesadores están configurados con un “Record Reader” y un servicio de “Record Writer Controller”. Hay Readers/Writers tanto para JSON, CSV o Avro.
Estos nuevos procesadores hacen que los flujos de construcción para manejar datos sean más sencillos. También significa que podemos construir procesadores que acepten cualquier formato de datos sin tener que preocuparnos por el análisis y la lógica de serialización. Otra gran ventaja de este enfoque es que podemos mantener los archivos FlowFiles más grandes, cada uno de los cuales consta de múltiples registros, lo que resulta en un rendimiento mucho mejor.
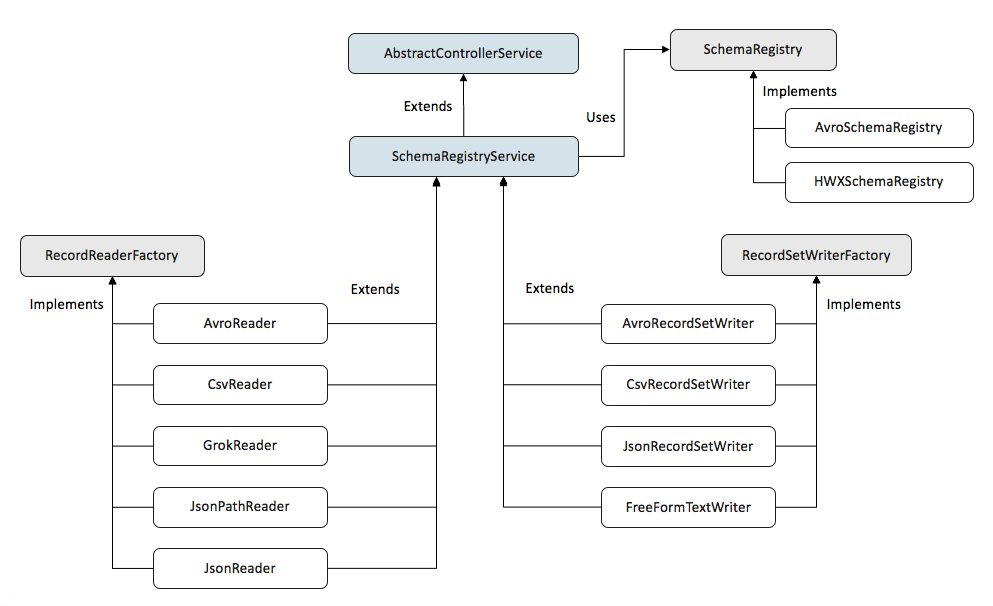
En el momento de escribir este artículo, existen los siguientes “Readers”:
- AvroReader
- CsvReader
- GrokReader
- JsonPathReader
- JsonTreeReader
- ScriptedReader
Y lo mismo para los “Writers”:
- AvroRecordSetWriter
- CsvRecordSetWriter
- JsonRecordSetWriter
- FreeFormTextRecordSetWriter
- ScriptedRecordSetWriter
Algunos ejemplos de “Record Processors” son:
- ConvertRecord, que convierte entre formatos y/o esquemas similares. Por ejemplo, la conversión de CSV a Avro se puede realizar configurando ConvertRecord con un CsvReader y un AvroRecordSetWriter. Además, la conversión de esquemas entre esquemas similares se puede realizar cuando el esquema de escritura es un subconjunto de los campos del esquema de lectura o si el esquema de escritura tiene campos adicionales con valores propuestos.
- LookupRecord, que extrae uno o más campos de un registro y busca un valor para esos campos en un LookupService. Los resultados se pueden volver a añadir al registro especificando una ruta de registro de destino. Por ejemplo, si los registros del archivo de flujo contienen un campo llamado ‘ip’ que contiene una dirección IP, podemos añadir una propiedad llamada ‘ip’ con un valor como ruta de registro ‘/ip’ y utilizar un IPLookupService para enriquecer nuestros registros con información sobre la dirección IP.
- QueryRecord, que ejecuta una declaración SQL contra los registros y escribe los resultados en el contenido del archivo de flujo. La mejor manera de explicar esto es leer esta entrada del blog.
- ConsumeKafkaRecord_0_10, este procesador usará el “reader” de registros configurado para deserializar los datos sin procesar recuperados de Kafka, y luego usará el “writer” de registros configurado para serializar los registros al contenido del archivo de flujo.
- PublicarKafkaRecord_0_10, este procesador usará el “reader” de registros configurado para leer el archivo de flujo entrante como registros, y luego usará el “writer” de registros configurado para serializar cada registro para publicarlo en Kafka.
Apache NiFi Schemas & Schema Registries
Para tratar el contenido de un archivo de flujo como “Records”, necesitamos una forma de interpretar ese contenido, y eso se hace a través de un esquema. Un esquema define la información sobre un registro, como los nombres de campo, los tipos de campo, los valores propuestos y los alias. Cada “Reader” y “Writer” tiene un “Schema Access Strategy” que le indica cómo obtener un esquema, y las opciones pueden ser diferentes dependiendo del tipo de lector o escritor.
Por ejemplo, un CsvReader puede elegir crear un esquema sobre la marcha utilizando los nombres de columna del encabezado del CSV, y un GrokReader puede crear un esquema a partir de las partes nombradas de la expresión Grok, pero estas dos opciones sólo se aplicarían a esos lectores respectivos.
En general, todos los “Readers” y “Writers” tienen la opción de usar Apache Avro para definir un esquema, incluso cuando el formato no es Avro mismo. Existen varias opciones para obtener un esquema Avro, tales como:
- Schema Name, proporciona el nombre de un esquema para buscarlo en el Schema Registry.
- Schema Text, proporciona el texto de un esquema directamente a los “Readers/Writers”, o utiliza EL para obtenerlo a partir de un atributo de un archivo de flujo.
- HWX Content-Encoded Schema Reference, el contenido del FlowFile contiene una referencia a un esquema en un servicio de Schema Registry.
- HWX Schema Reference Attributes, el FlowFile contiene 3 atributos que se usarán para buscar un esquema desde el Schema Registry configurado: ‘schema.identifier’, ‘schema.version’, y ‘schema.protocol.version’.
Actualmente se prestan dos servicios de Schema Registry:
- AvroSchemaRegistry, un registro de esquemas local a una instancia Apache NiFi dada que soporte la recuperación de un esquema por nombre.
- HortonworksSchemaRegistry o ConfluentSchemaRegistry, instancias externas que admiten la recuperación de un esquema por nombre o por Id. y versión.
Apache NiFi Scheduling & Component Versions
Apache NiFi tiene acceso a información sobre la versión de sus procesadores, servicios de controlador y tareas de informes. Esto es especialmente útil cuando se trabaja en un entorno agrupado con múltiples instancias de Apache NiFi que ejecutan diferentes versiones de un componente o si se ha actualizado a una versión más reciente de un procesador.
Los cuadros de diálogo de “Add Processor”, “Add Controller Service” y “Add Reporting Task” incluyen una columna que identifica la versión del componente, así como el nombre del componente, la organización o grupo que creó el componente y el conjunto de NAR que contiene el componente.
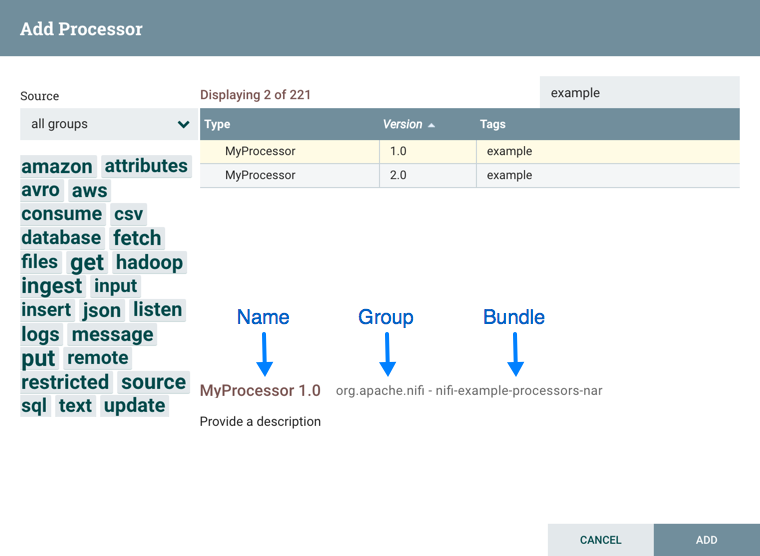
Existen tres opciones posibles para Scheduling de componentes:
-
Timer driven: Este es el modo por defecto. El procesador se programará para que se ejecute a intervalos regulares. El intervalo en el que se ejecuta el procesador se define mediante la opción “Run Schedule”.
-
Event driven: Cuando se selecciona este modo, el procesador se activará para que se ejecute por un evento, y ese evento se produce cuando los FlowFiles entran en Conexiones que alimentan a este procesador. Cuando se selecciona este modo, la opción “Run Schedule” no es configurable, ya que el procesador no se activa para ejecutarse periódicamente sino como resultado de un evento. Además, este es el único modo para el que la opción “Concurrent Tasks” se puede establecer en 0. En este caso, el número de hilos está limitado sólo por el tamaño del grupo de hilos controlado por eventos que el administrador ha configurado.
-
CRON driven: Cuando se utiliza el modo de programación controlado por CRON, el procesador se programa para que se ejecute periódicamente, de forma similar al modo de programación controlado por temporizador. Sin embargo, el modo CRON proporciona una flexibilidad significativamente mayor a costa de aumentar la complejidad de la configuración.
La pestaña de Programación proporciona una opción de configuración llamada “Concurrent Tasks”. Esto controla cuántas hebras utilizará el procesador. Dicho de otra manera, esto controla cuántos FlowFiles deben ser procesados por este procesador al mismo tiempo. Aumentar este valor normalmente permitirá al procesador manejar más datos en la misma cantidad de tiempo. Sin embargo, lo hace utilizando recursos del sistema que no son utilizables por otros procesadores. Esto esencialmente proporciona una ponderación relativa de los procesadores y controla la cantidad de recursos del sistema que deben asignarse a este procesador en lugar de a otros procesadores. Este campo está disponible para la mayoría de los procesadores. Sin embargo, existen algunos tipos de procesadores que sólo pueden programarse con una sola tarea concurrente.
Apache NiFi Variables
Las variables se incluyen cuando un grupo de procesos se coloca bajo control de versiones. Si se importa un flujo versionado que hace referencia a una variable no definida en el grupo de procesos versionado, la referencia se mantiene si la variable existe. Si la variable de referencia no existe, se definirá una copia de la variable en el grupo de proceso.
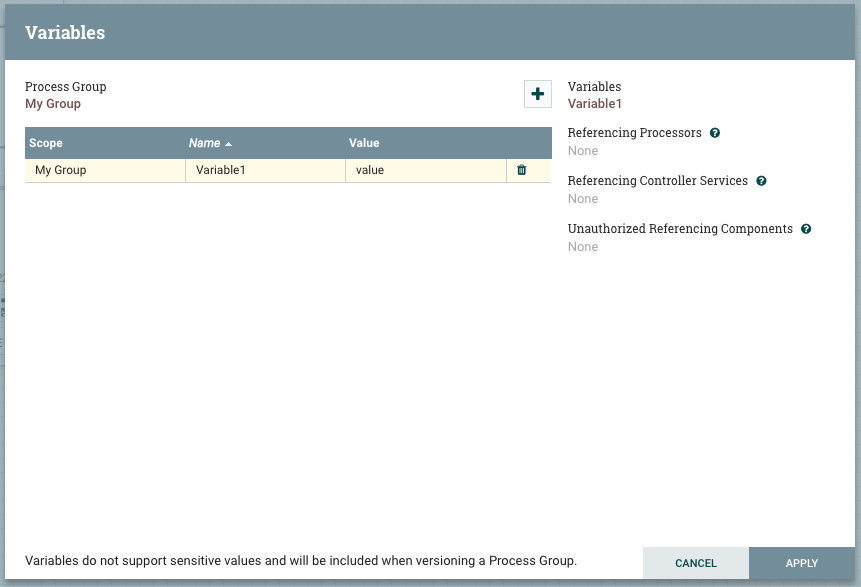
La tabla lista todas las variables que están disponibles en el ámbito del “Grupo de Procesos” actual, el nombre de la variable y el valor de la variable. Sólo las variables definidas en el “Grupo de Procesos” actual son editables. La tabla también contiene un enlace de navegación para ir al “Grupo de Procesos” donde se definen las variables heredadas. En la parte derecha del diálogo se muestra la variable seleccionada en la tabla junto con todos los componentes que hacen referencia a ella.
Los Procesadores y Servicios de Controladores encapsulados en el actual Grupo de Procesos tendrán acceso a las variables definidas en ese Grupo de Procesos y en todos los Grupos de Procesos ancestrales. Si un Grupo de Procesos anidado define una variable con el mismo nombre que una definida en un ámbito superior, anulará ese valor. Esto se visualiza en el diálogo Variable usando un tachado. Este proceso de anulación se puede resumir diciendo que cuando un componente hace referencia a una variable, el valor vendrá de la definición más cercana.
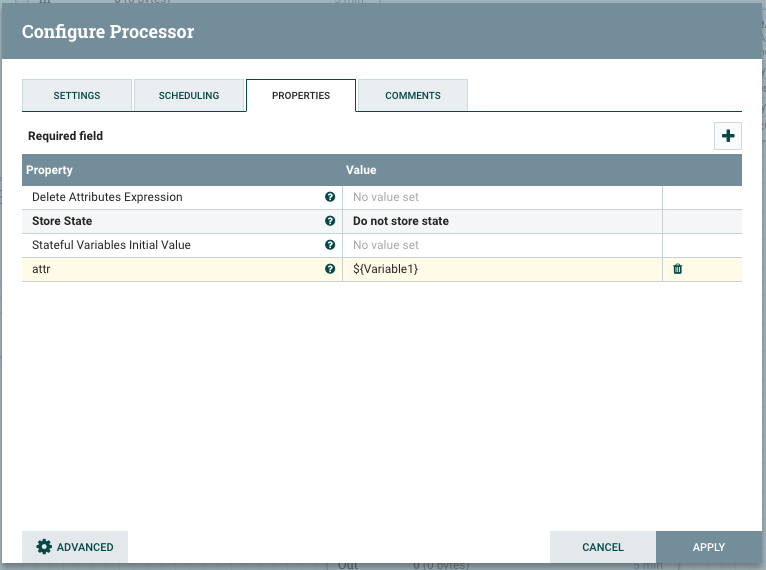
La referencia a una variable se hace usando el lenguaje de expresión. Si una propiedad Processor o Controller Service soporta lenguaje de expresión, se puede utilizar un nombre de variable como subject.
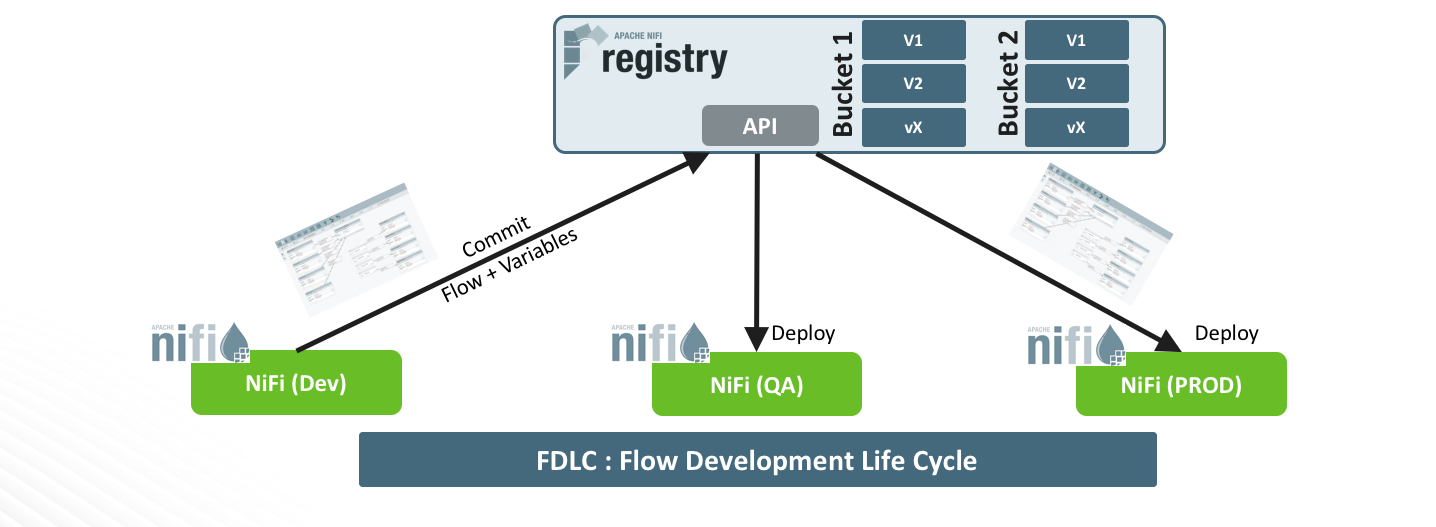
Apache NiFi Registry
Apache NiFi Registry es un subproyecto de Apache NiFi complementario que proporciona una ubicación central para el almacenamiento y la gestión de recursos compartidos a través de una o más instancias de NiFi y/o MiNiFi.
La característica principal de Apache NiFi Registry son los flujos versionados. Los flujos de datos a nivel de grupo de procesos creados en NiFi se pueden colocar bajo control de versiones y almacenar en un registro. El registro organiza dónde se almacenan los flujos y gestiona los permisos para acceder a ellos, crearlos, modificarlos o eliminarlos.
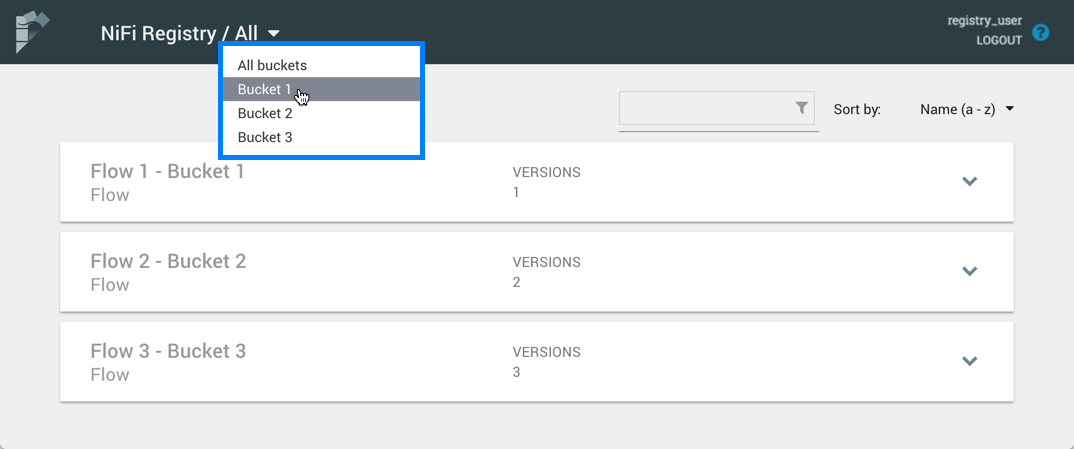
Para probar las características del “flow registry”, primero empezaremos creando un nuevo grupo de procesos y, como seguramente, si utilizado por ejemplo un broker Kafka será diferente cuando estemos en Dev o en Prod, por lo tanto usaremos variables para el host del broker, el puerto y el nombre del “topic. Para ello, revisaremos la configuración del grupo de proceso y luego en las variables añadiremos tres nuevas, una para el host, otra para el puerto y otra para el “topic” name.
Estas variables son manejadas por el framework NiFi y almacenadas en el archivo de definición de flujo (flow.xml). Hay una sección “variable” al final de cada sección de grupo de proceso que lista las variables definidas y sus valores. Como vimos en una anterior imagen, podemos utilizar de forma simple las variables y en éste caso no será menos.
Para poder guardar el flujo en el “flow registry”, iremos al grupo de procesos raíz e iniciaríamos el control de versiones. Terminamos con una ventana en la que se nos pide que configuremos el nombre del flujo, la descripción del flujo y los comentarios de la versión.
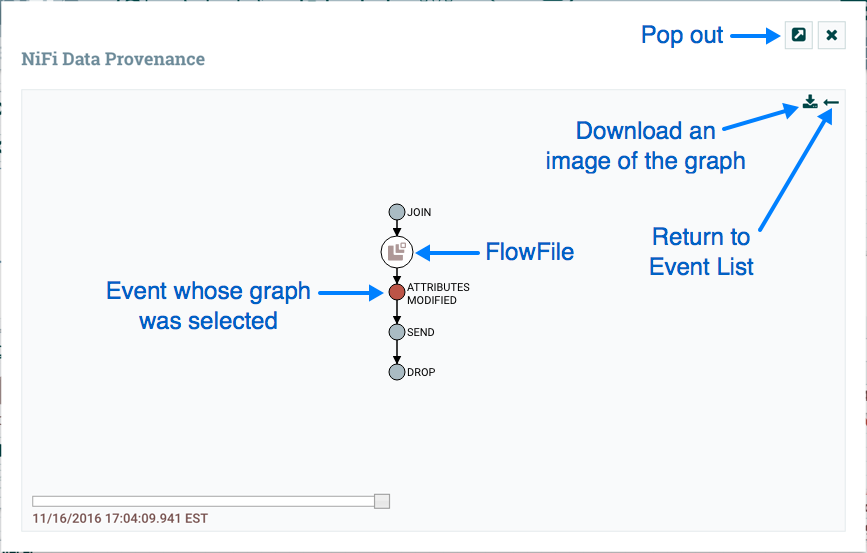
Apache NiFi Data Governance
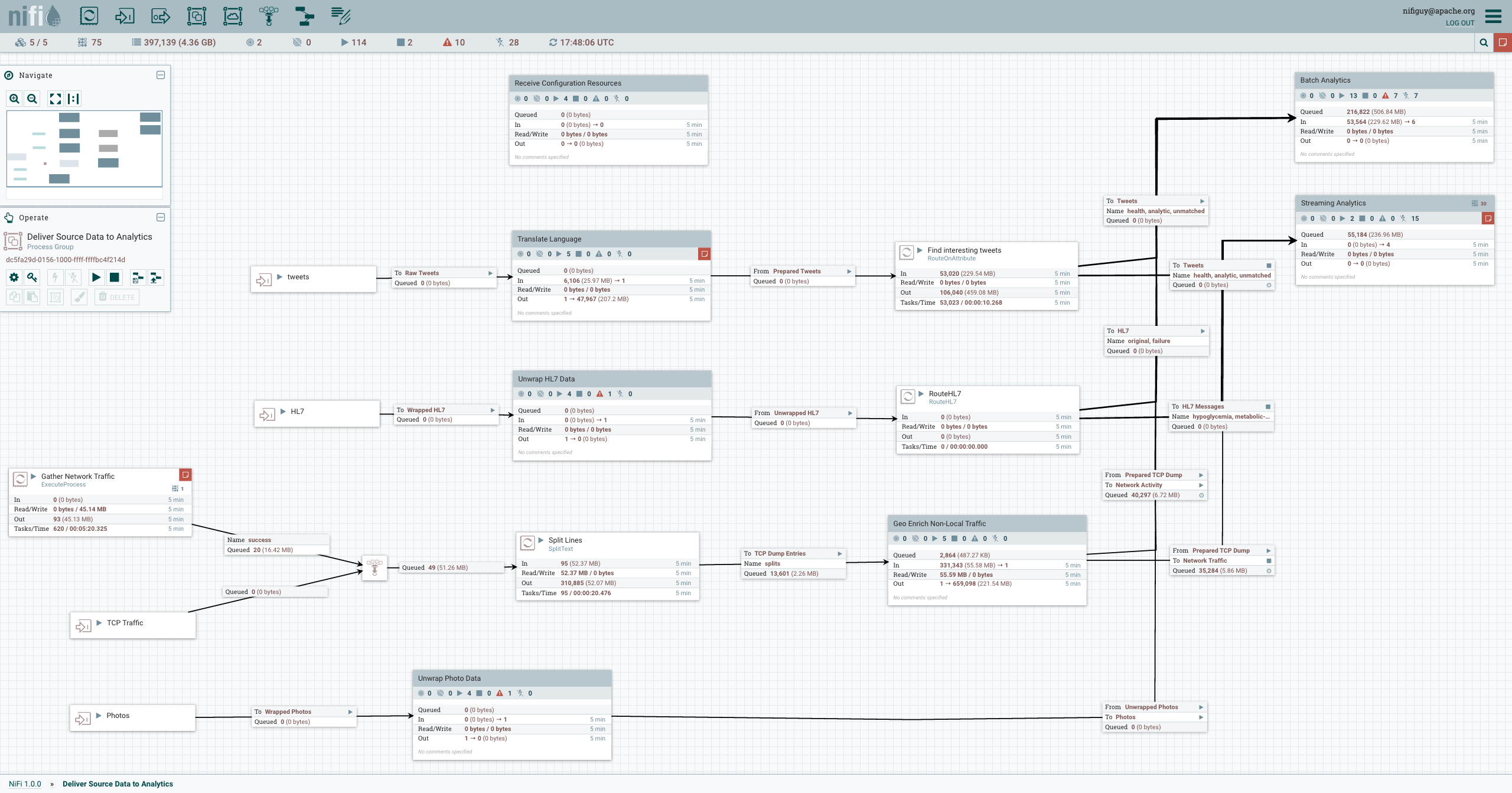
Gracias a los eventos que se generan en Apache NiFi, podemos generar una completa #Data-Governance, por ejemplo en la imagen que acompaña se puede observar el detallecon que Apache NiFi nos muestra los datos que se han sucedido en el tiempo.
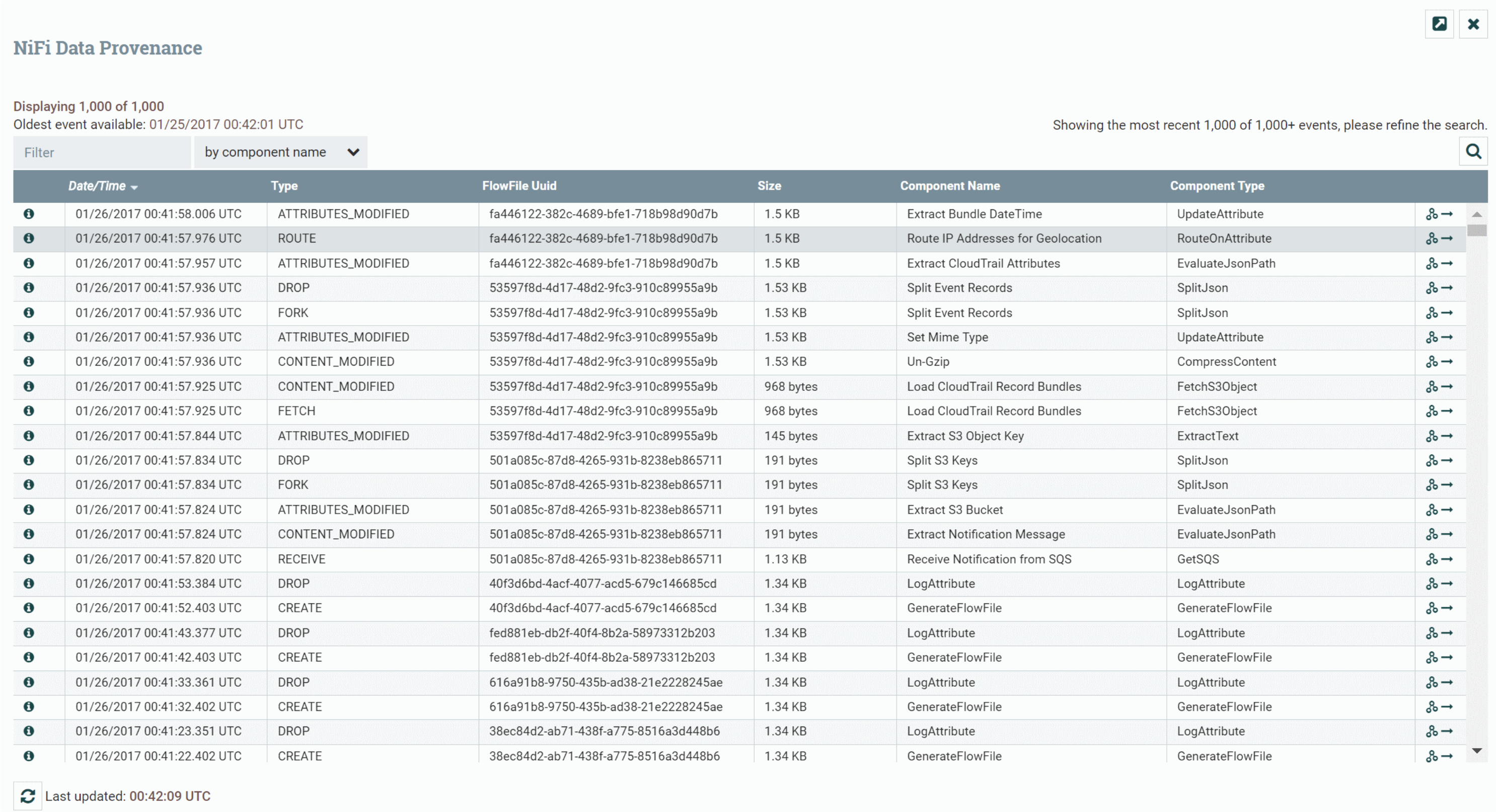
Apache NiFi Flow Management
Naturalmente, una gran ventaja de usar Apache NiFi es la posibilidad de gestionar, rápidamente, los flujos que se creen. Conectarlos entre sí o, aplicar lógica de negocio en caso que se requiera. Entre proceso y proceso, también, podemos aplicar una simple “queue” que puede facilitarnos y mucho el trabajo. Veamos un ejemplo:
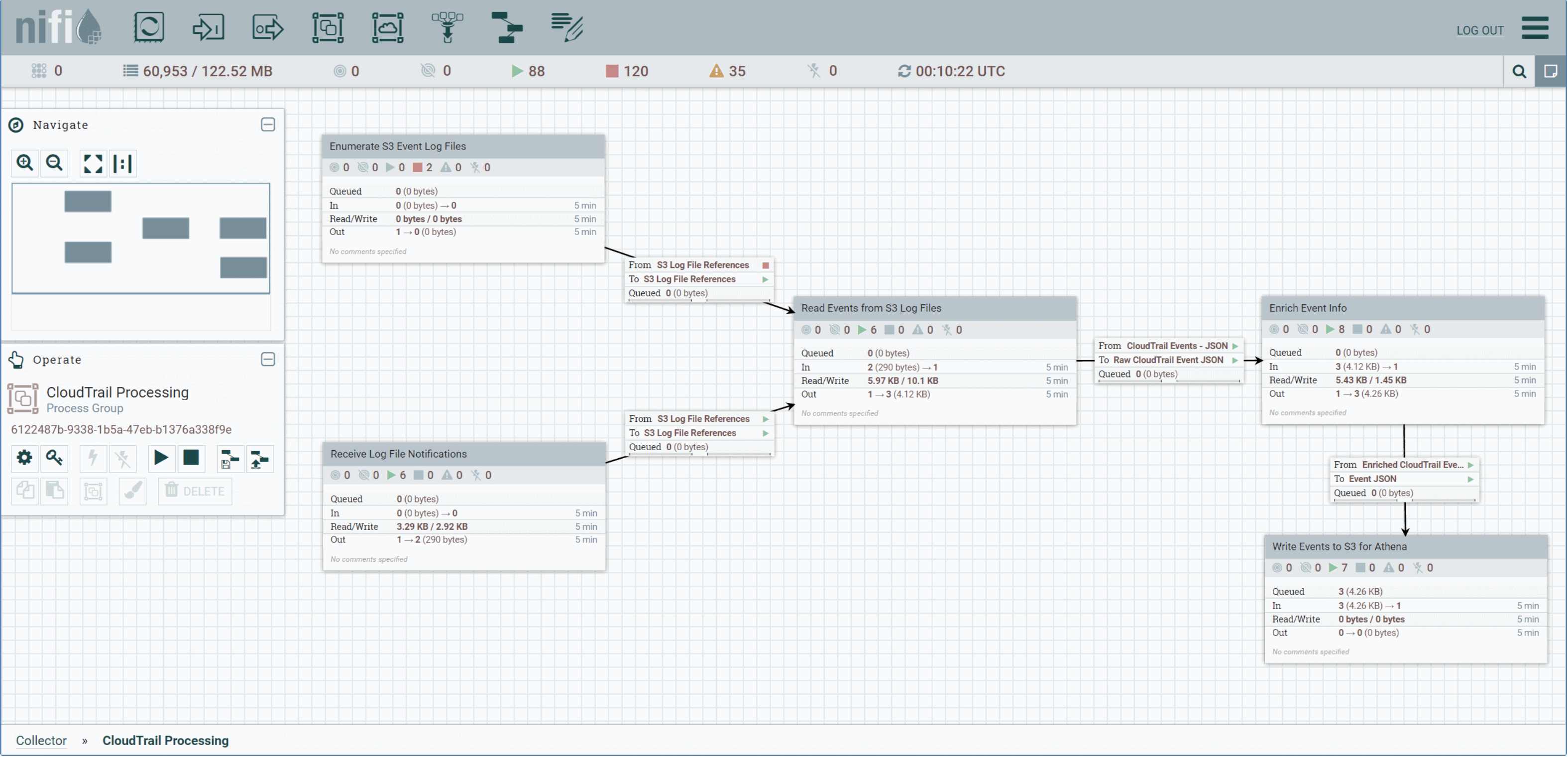
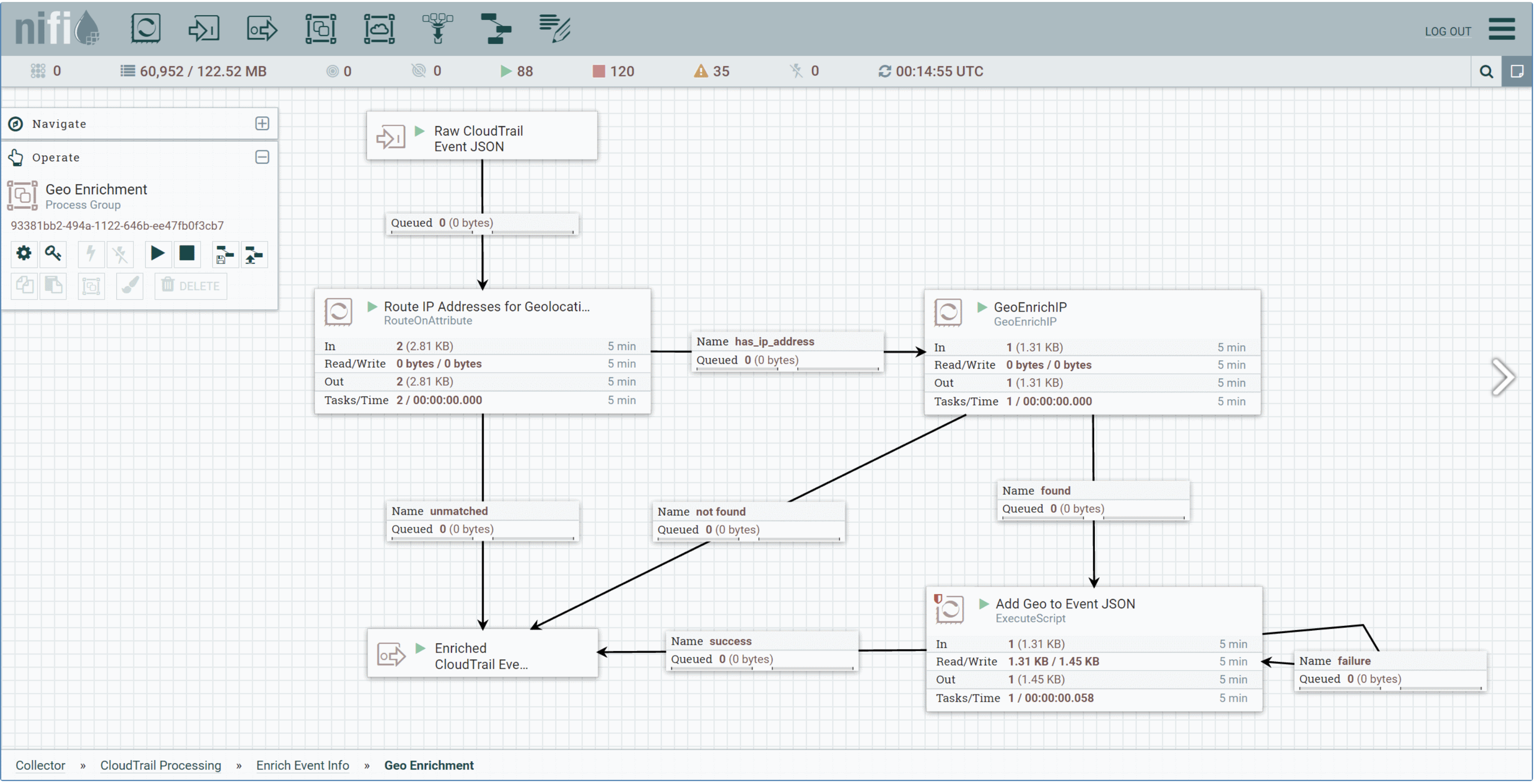
Apache MiNiFi
Apache MiNiFi, es un subproyecto de Apache NiFi, con un enfoque de recopilación de datos complementario a los principios básicos de Apache NiFi en la gestión del flujo de datos se refiere, centrándose en la recopilación de datos desde la fuente de su creación.

Apache NiFi Flow Monitoring
Con Apache NiFi también, de forma “nativa”, podemos monitorizar todos nuestros flujos y no tener que depender de otra herramienta. Rápidamente tendremos control de todos nuestros flujos y aplicar reglas en caso de necesidad.
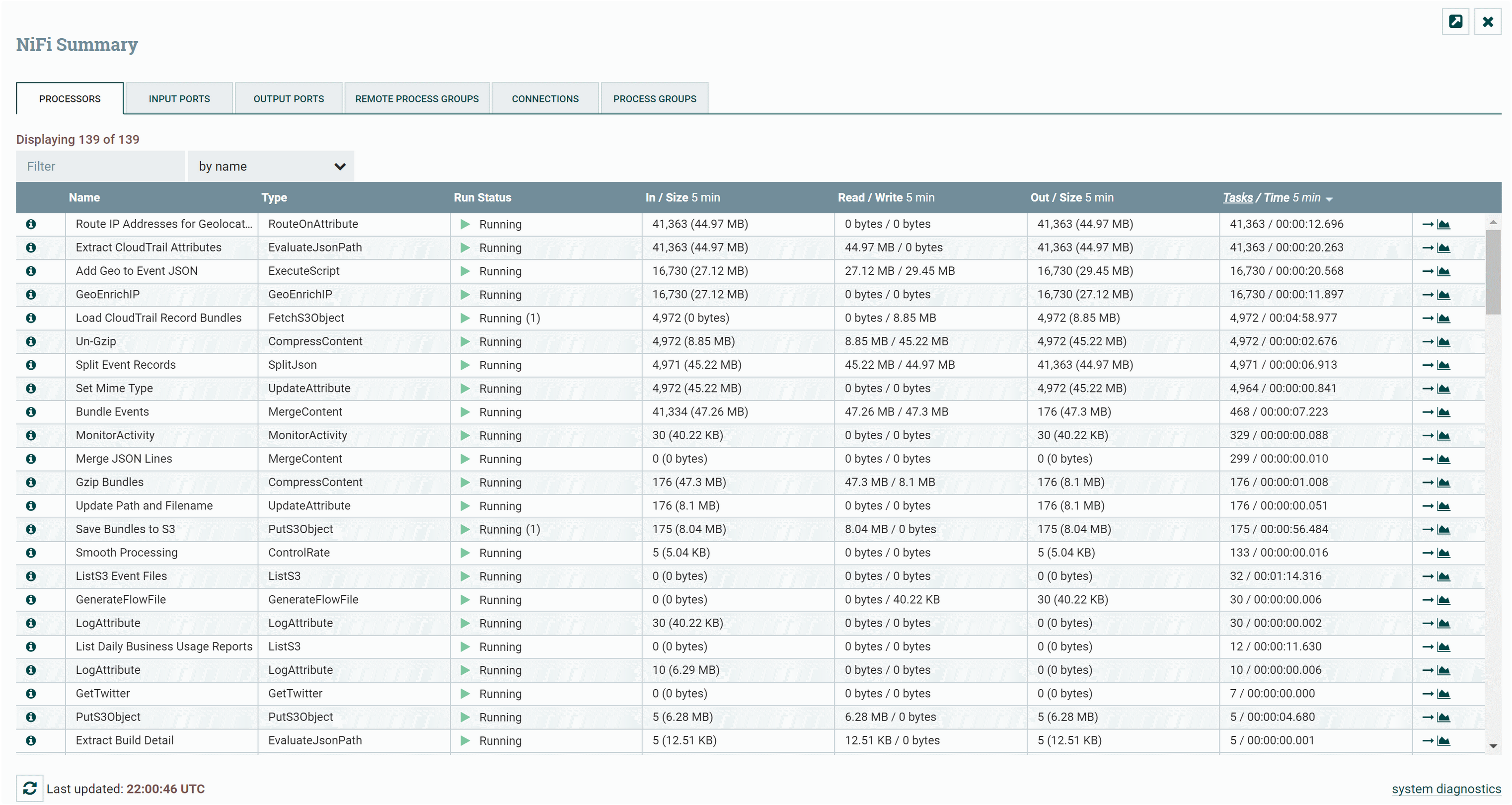
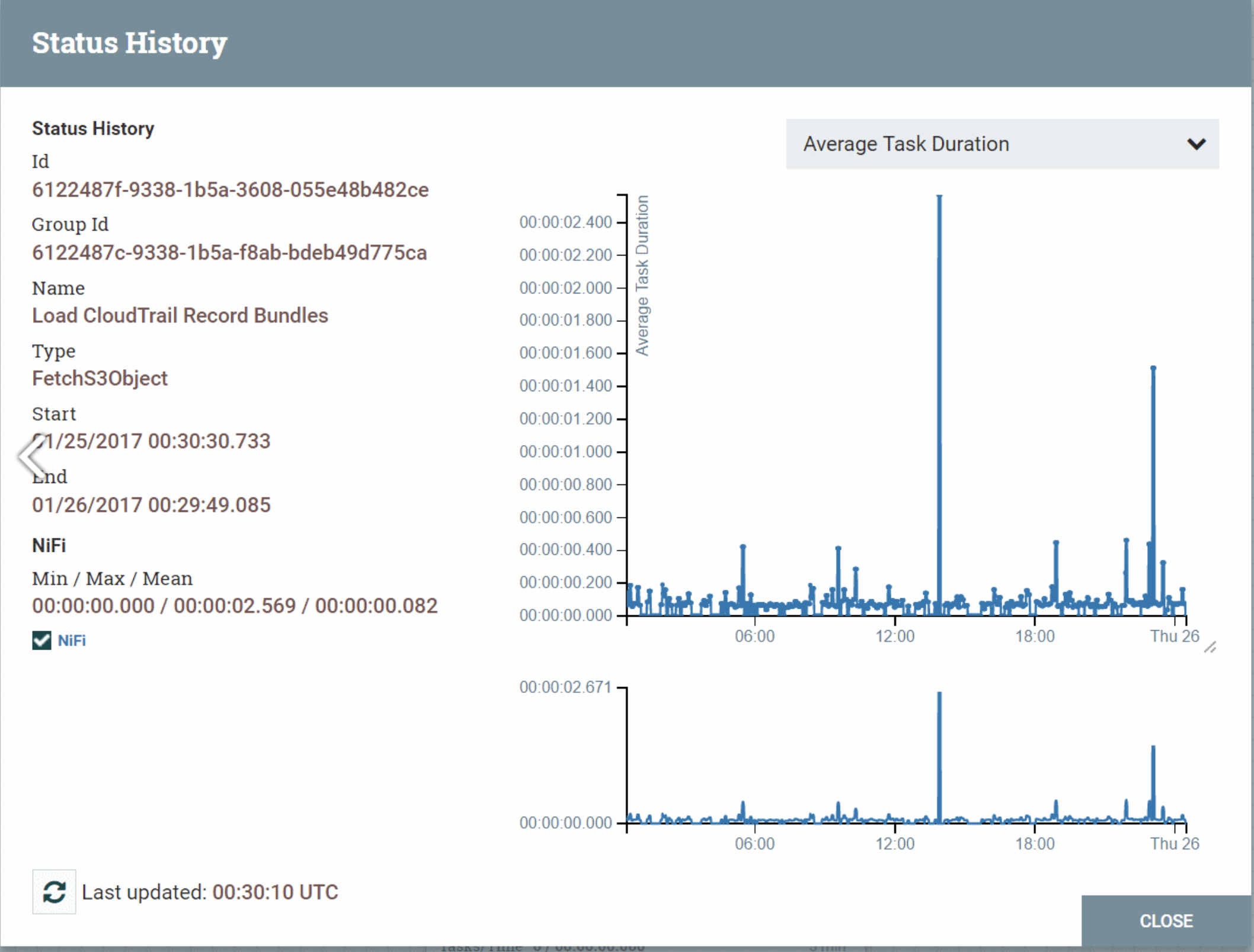
Como poder controlar la Performance de los mismos jobs, es decir, de una forma Global y de una forma unitária.
Advanced Data Streaming with Apache NiFi
Si hay un libro que me ha ayudado a mejorar mi conocimiento de Apache NiFi es “Advanced Data Streaming with Apache NiFi: Engineering Real-Time Data Pipelines for Professionals”, el cual es un libro muy recomendado para continuar profundizando en el tema.