Database Scalability
Hoy en día uno de nuestros grandes retos es poder escalar, en el momento oportuno y durante el tiempo necesario (no más de lo necesario, por su impacto en costes). Para poder dar solución, por lo general, nuestras arquitecturas han ído sufriendo cambios, introduciendo balanceadores de carga, para distribuir el tráfico de forma horizontal (que no vertical) y introduciendo también caché en la cap de publicación.
Con la introducción del Cloud y más concretamente de sus servicios PaaS, nos hemos podido “olvidar” un poco de estos escalados tanto en la parte de publicación como también en la parte de base de datos, que es mucho más complejo el escalado ya que, la aplicación también debe estar preparada para atacar a “múltiples” bases de datos. No siempre pasa eso. Pero, al final, podíamos tener rápidamente esta situación:
- Una capa de balanceo para la publicación, que a partir de múltiples nodos con escalado horizontal podían asumir el tráfico web y servirlo a nuestros visitantes.
- Una base de datos monolítica con crecimiento vertical y, máximo, máximo, varias bases de datos que dan servicio según componente pero, al final, siguen siendo una base de datos con opciones de reader/writer para cubrir las necesidades.
Esto, a la larga, no era sostenible o bien, los costes en infraestructura se disparan por la necesidad de tener tallas muy grandes para poder sostenerlo. Es por ello que podemos tener varias soluciones que podrían aportar mucha luz y una importante reducción de costes si se aplica de forma correcta, veamos dos posibilidades:
Data Scaling Architectures
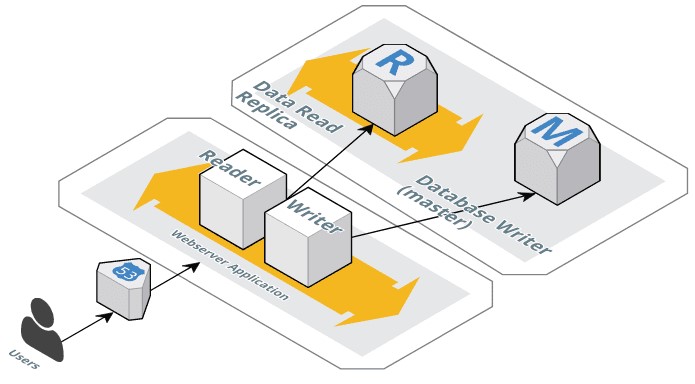
En ésta primera imagen tenemos un primer paso a transformar lo que comentamos anteriormente, es decir, preparar nuestra aplicación para poder atacar a un sistema de base de datos que escala, también. Pero que no solamente escala en vertical, sinó también en horizontal y según su caraterística.
En un primera paso, definimos que una instancia de base de datos de talla “X” será la Master, es decir, será que la haga el write de los datos.
En un segundo paso, definiremos una o varias, según nuestras necesidades, que de forma predeterminada estarán operativas para tener una Read replica de la base de datos Master. Por lo tanto, solo aceptaran procesos de lectura.
Este simple cambio en nuestra arquitectura, de entrada, nos permitirá una serie de mejoras, hagamos un pequeño listado:
- Poder escalar de forma automatizada una base de datos en modo Read Replica para poder dar servicio a la capa de publicación que, mayormente, hacen sólo ataques de lectura. Estamos hablando de páginas de información o procesos de consulta.
- Poder configurar una Read Replica según compontente, posiblemente tengamos componentes de nuestra aplicación, por ejemplo APIs, que deban tener una preferencia mayor respecto de otros. Pues démosles esa preferencia con recursos casi dedicados o dedicados y autoescalados también.
- Poder tener una instancia writer dedicada sólo y exclusivamente a esa función, separando así un % muy elevado de uso de la base de datos que, seguramente y siguiendo las afirmaciones anteriores, sólo son procesos de lectura.
En la imagen que acompaña el caso sólo mostramos los componente de publicación básicos y las bases de datos, naturalmente piezas como balanceadores, etc… no figuran en el diagrama. En este caso, tampoco las APIs, en el dibujo del caso siguiente, si visualizaremos las APIs.
Data Caching Architectures
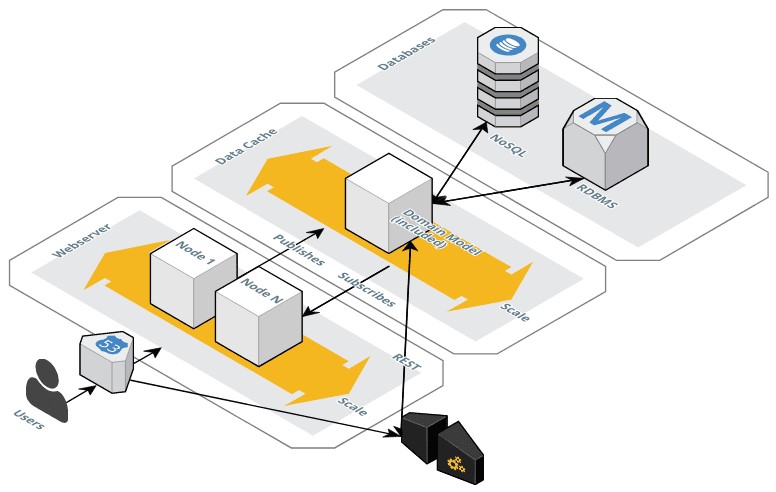
En esta segunda imagen, tenemos un diagrama distinto al anterior ya que, damos menos importancia a la capa de base de datos e introducimos un nuevo componente: Data Cache.
Quiero hacer un incapié en Data Cache ya que no estamos hablando de un cache en la capa de publicación, como podría ser Vasnish. Estamos hablando de una capa “más inteligente”, como podría ser: Elasticache con un Redis en su interio o Elasticsearch Service, ambos servicios de AWS u otras cosas como Hazelcast.
La gente de Hazelcast tienen un interesante artículo de comparativa entre sus servicios y otros, aquí mencionados.
No entraré a comparar las soluciones, me interesa más explicar los fundamentos. Por lo tanto, veamos con más detalle la imagen anterior:
- Por un lado continuamos teniendo el mismo modelo de entrada, donde “N” nodos autoescalados darán servicio de publicación de nuestra aplicación, con sus balanceadores, etc…
- Y por otro lado, tendremos un API Gateway, para aquellos accesos programáticos que podamos tener.
Dejando a parte piezas que, con mucho más detalle se tendrían que treabajar, por ejemplo las APIs, entraremos a explicar el fundamento. Veamos de nuevo:
Al establecer una capa de Data Cache podremos, por ejemplo, volcar en ella nuestro Modelo de datos o Domain Model. Para no solamente hacer un simple cache de datos, sinó tambien poder indexar y establecer ciertos criterios de negocio e inteligencia.
A su vez, podremos establecer procesos que hagan una publicación de datos hacia la Data Cache y otros que hagan un consumo (Subscriber). Por lo tanto, dejaremos a la capa de Data Cache la interacción al 100% con la o las bases de datos que podamos tener tras ella.
También, esta capa de Data Cache podría interactuar con otras tipologías de arquitecturas como: REST (ara las APIs). Estaríamos hablando que el tiempo de cache que tienen los sistemas más tradicionales, aquí no se vería afectado ya que al tener también los cambios podría entregar realtime para su consumo.
High Performance & High Availability
De tipologías de Arquitectura de infraestructura hay muchas pero, así de entrada, podemos diferenciar entre: “High Performance” y “High Availability”. Que por cierto, podemos implementar las dos en una misma, por ejemplo, nuestro post de hoy. Vamos a ver una arquitectura, bastante económica, para poder tener el siguien esquema lógico: Acceso de los usuarios > Validaciones > Retorno de datos > Ingestión de información (Evento) > Transformación de la Información >Indexación > Visualización (Explotación). En el siguiente diagrama lo podemos ver representado, a continuación, comentaremos brevemente los pasos.
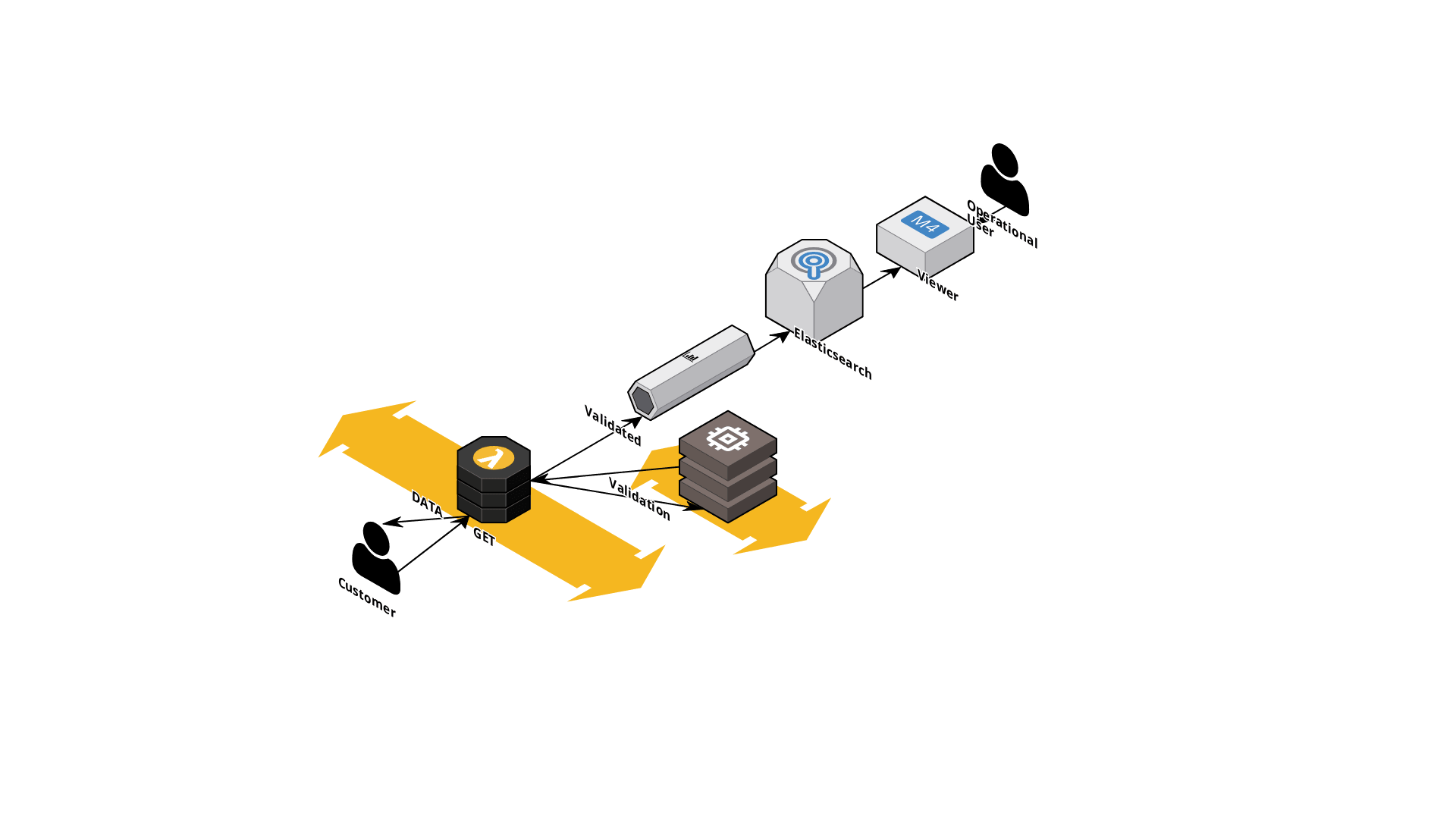
Acceso de usuarios + Validaciones iniciales
Imaginemos que nuestros usuarios acceden a nuestro servicio, pero que antes necesitaremos recogerles una información para servirles un contenido más adecuadas. Estamos hablando por ejemplo de servicios que sirven contenido distinto según zona geográfica, tipo de dispositivo móvil, tipo de suscripcion, etc… Una vez recogida esta información, que a través de una pieza de networking (no representada en el diagrama) se conducirá a una function o AWS Lambda en nuestro caso.
Ésta tendrá la misión de realizar la validación del servicio y, vemos en el diagrama, lo realizará contra una base de datos en memoria del tipo Redis (AWS ElastiCache), por ejemplo. También, importante, podemos ver (flechas amarillas) que tendrá la posibilidad auto-escalarse (High Availability) de forma automática y según necesidad de nuestro servicio. ¿Qué pasaría si acceden miles de usuarios a nuestro servicio? ¡Pues tenemos que tenerlo controlado!.
Data Stream
Una vez realizadas las validaciones, capturaremos el o los distintos eventos (event-driven), que serán recogidos por proceso basado en Streams y utilizando AWS Kinesis (o Kafka) para ello. Dentro del mismo proceso en Streams podremos aplicarle un proceso de transformación (EMR) del dato para convertir, si requerimos, el RAW Data recogido en un dato normalizado o entendible para nuestra Solución (opcional); sinó, entregaremos el dato tal cual al siguiente componente.
Indexación de la información + Visualización
En nuestro ejemplo de hoy no estamos sirviendo la información a una aplicación, sinó a la necesidad de tener controlados los accesos a los servicios y es por eso que el siguiente componente es otra base de datos en memoria pero, basada en índices. ¿Motivo?, el poder tener la información categorizada por necesidades. Es decir: podemos imaginar que tendremos un indice global o por tipología de servicio, etc… irá en función de nuestras necesidades. La idea será, luego, podemos recuperarlo en formato visualización mediante un Kibana u otra herramienta de Data Visualization.
La suma de los componentes de Elasticsearch y Viewer (ELK) nos van a permitir tener controlado, en casi realtime, nuestros servicios y que usos se les están dando.
Lo más importante de todo es que esta Arquitectura, en AWS, tendrá un coste aproximado de 500€/mensuales, bastante asumible para empreses que requieren un tratamiento alto de información y que su gran Valor es el poder tratarla como tal: en realtime.