¿Podemos poner en un ring de boxeo dos tipologías de arquitecturas como son la ingestión de datos mediante BPMs o con eventos? Creo no es acertado ponerlas a competir pero si, podemos explicarlas por separado y afrontar, según nuestras necesidades y/o posibilidades, cual de las arquitecturas podemos llevar a cabo.
También es cierto que muchas veces nos lo encontraremos dado, por ejemplo cuando tenemos delante una aplicación o servicio más tradicional, sea un ERP, un CRM, etc… aquí será muy complejo el poder llegar a un proceso de generación de eventos ya que, seguramente, deberíamos afrontar una transformación casi por completo de la aplicación.
Es por ello que, a continuación, presento una imagen con dos diagramas:
- El primero enfocado a una arquitectura que conecta fuentes de datos, claramente identificadas, y que tras un proceso de workflows o BPMs ingestamos a nuestro sistema de “Streams”.
- El segundo enfocado a un proceso “nativo” de Stream Analytics. Donde un sistema basado en eventos dará distribución de los datos según nos interese.
En este post comentaremos el primero, veamos…
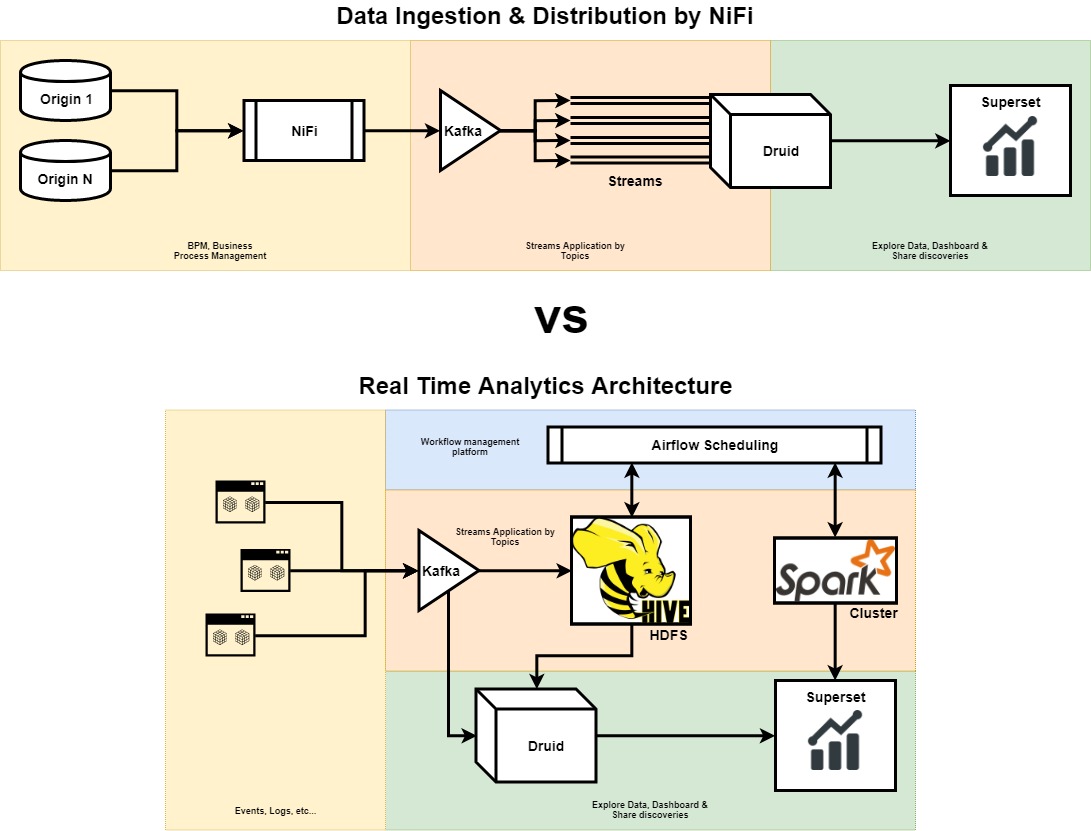
Data Ingestion & Distribution by Apache NiFi
Supongamos que tenemos dos aplicaciones, con dos bases de datos operacionales SQL y también que tenemos identificados nuestros procesos de negocio y como éstos nos permiten construir un proceso basado en workflows para extraer aquellos datos que otros sistemas requieren. Por ejemplo: dashboards de cuadros de mando.
En el siguiente diagrama, que es un “cut” del primero, veremos de izquierda a derecha que tenemos identificadas una série de base de datos y, seguidamente un proceso basado en Apache NiFi. Ésta sección la vamos a llamar “BPM, Business Process Managament” y será la encargada de poder inyectar datos estructurados a nuestra Pipeline de salida.
Apache NiFi
De NiFi ya hemos hablado anteriormente y es bastante simple su utilización, rápidamente nos podemos montar una Pipeline que conecte una fuente de datos con otra, aplicando un proceso de transformación o normalización de datos; para nuestro caso actual será un buen aliado y muy recomendable.
Apache Kafka
Una vez tenemos identificados, como decíamos, las fuentes de datos y conectadas a nuestra Pipeline diseñada en NiFi es la hora de hablar de Apache Kafka, de quien, también, hemos comentado con varios post anteriormente y que sin duda alguna no tiene competidor en su categoría. Kafka nos ayudará a convertir un proceso tradicional de ETL en Streams. Es decir, una vez tengamos clasificadas nuestras entidades, por ejemplo si venimos de un CRM: contactos, incidencias, usuarios, etc… podremos convertirlas a “Streams” mediante la clasificación por Topis que hemos aplicado en Kafka. ¿Cómo lo haremos? Conectando al ouput de Kafka dos posibles soluciones: Apache Samza o Apache Flink.
Streams
Nuestra idea principal es poder aplicar un sucedáneo de la arquitectura Kappa utilizando su modelo para que en vez de usar datos ya almacenados en bases de datos origen, utilizemos flujos de datos o “streams”. Estos Streams los enviaremos mediante un sistema de procesado y los almacenaremos en un otro sistema auxiliar de nuestra capa de servicio. La voluntad será poder consumir datos más cocinados, normalizados, etc…
Antes que nada, realicemos una tabla comparativa entre Apache Samza y Apache Flink, nuestras propuestas, para tomar la mejor decisión en cuanto a necesidades más particulares:

Apache Samza:
Apache Samza es un sistema distribuido de “Stream Processing” y está basado en Apache Kafka para la mensajería como en Hadoop YARN para proporcionar tolerancia a fallos, seguridad, independencia de procesos y gestión de recursos. Sus dos principales características:
- La transmisión se basa en un sistema de verdades construido, principalmente, sobre Apache Kafka y se requiere el manejo de estados.
- Está basado en un sistema API de bajo nivel
Apache Flink:
Apache Flink es un motor de procesamiento de streams o flujos de datos que nos proporciona tanto capacidades de distribución de datos, como de comunicaciones como también a la tolerancia a fallos. Es de alto rendimiento y con el objetivo de estar siempre disponible como preciso. Sus dos principales características:
- La transmisión se basa en un sistema de verdades con compensación de latencia vs rendimiento ajustables.
- Está basado en un sistema API funcional y enriquecida que explota el tiempo de ejecución de la transmisión.
Druid
Druid.io es un almacén de datos (se hace sobre S3 o HDFS) analítico, Open Source, diseñado para poder realizar consultas (JSON) de inteligencia empresarial (OLAP) sobre datos basados en eventos. Druid nos va a proporcionar una ingestión de datos de baja latencia y en tiempo real para una exploración flexible de datos y, también, la agregación rápida de datos.
Druid está inspirado en las BigQuery o PowerDrill de Google y en otras infraestructuras de búsqueda. Mediante la solución, por ejemplo, podremos indexar los datos para crear distintas vistas, almacenar los datos en formato columnar para reaizar tanto agregaciones como filtros y aquí es donde, mediante la conexión anterior vía Streams, daremos un Valor Añadido a nuestra solución global, ya que estaremos “transformando” nuestra capa relacional y/o operacional a eventos y lo podremos gestionar de forma multi-tenancy y nos va a permitir desarrollar aplicaciones analíticas para miles de usuarios concurrentes
Podemos explorar más sobre Druid vs algunas soluciones existentes y quizás, más conocidas, del tipo:
- Druid vs Elastixsearch: http://druid.io/docs/latest/comparisons/druid-vs-elasticsearch.html
- Druid vs Redshift: http://druid.io/docs/latest/comparisons/druid-vs-redshift.html
- Druid vs Spark: http://druid.io/docs/latest/comparisons/druid-vs-spark.html
Caso ING
En el siguiente Diagrama tenemos el caso que vamos a explicar:
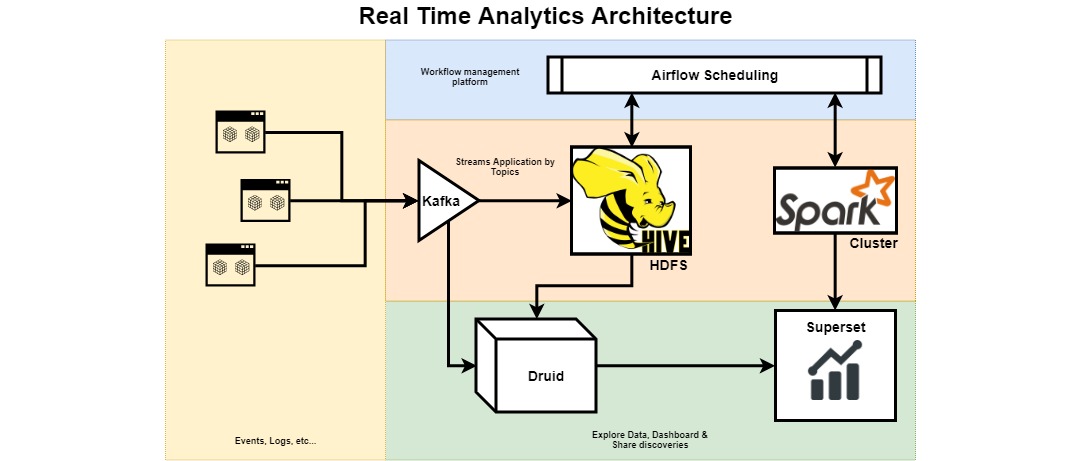
Partimos de unas aplicaciones o Microservicios que hemos diseñado y, a su vez, que hemos diseñado con un sistema de eventos; también, podríamos estar ingestando logs pero ahora vamos a ver aplicaciones que gestionan eventos y que nos informaran por cada cambio que tienen origen o destino en nuestra aplicación.
Nuestra aplicación, mediante un sistema push, informará de aquellos cambios de información que le están sucediendo, informará a un broker Kafka donde ya se clasificará mediante Topics para, seguidamente, poder ingestarlo según estipulemos.
Como ya comentamos en posts anteriores, Kafka nos va a permitir tener no solamente una clasificación previa a la ingestión sinó también un sistema de buffer para que en caso de tener puntas de envío de información poder asumirlo con crecimiento horizontal y un Alto throughput de ingesta.
Ahora, veamos el ejemplo de ING:
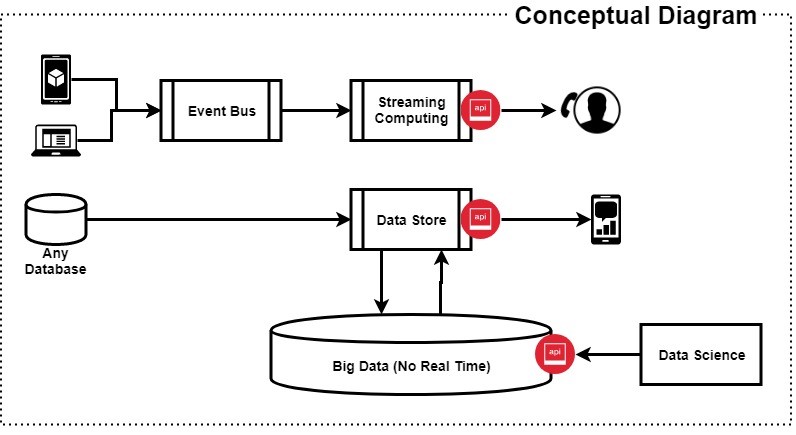
En éste primer diagrama podemos ver un mapa conceptual de la Arquitectura, dónde tiene mucho parecido justo con nuetras anterior explicación. Un conjunto de aplicaciones que mediante la generación de eventos se comunican con un sistema distribuido de streams que, finalmente, otra aplicación recoge y gestiona. Seguidamente, un conjunto de orígenes de datos, mayormente SQL y mediante un sistema de Pipeline ingestan datos a un Data Store centralizado donde un sistema de Big Data se conecta y genera las nuevas informaciones. Ahora, veamos la parte lógica, quizás más interesante para nosotros:
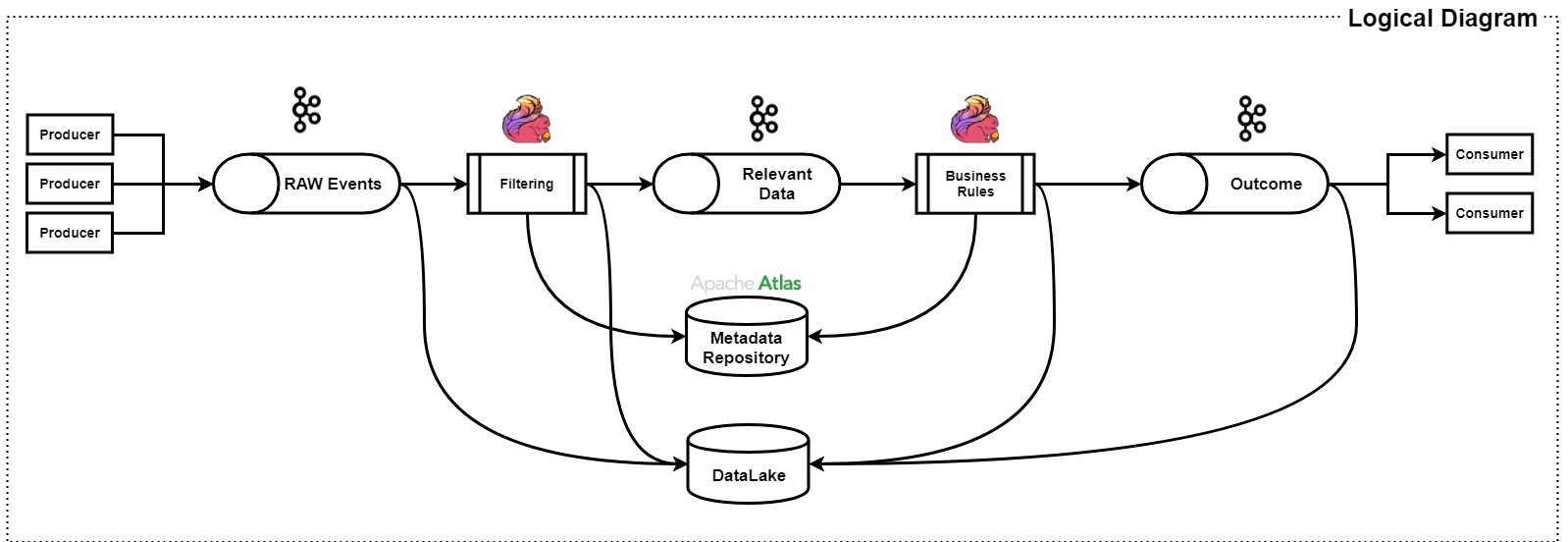
Básicamente el diagrama que acabamos de ver es, varias veces, el proceso de stream que hemos comentado. De izquierda a derecha podemos ir viendo los pasos que se realiza para is ingestando la información como a su vez, darle valor y limpieza a la misma. Primero tenemos un conjunto de fuente productoras de información que ingestan a un sistema Kafka los eventos generados, Flink mediante un conjunto de business rules realiza una limpieza de las mismas como, también, ingesta en un sistema de Metadata aquellos datos que irán construyendo el catálogo de datos para poder generar índices de información que complementarán nuestro sistema y nos facilitarán búsquedas, por ejemplo. Éste sistema de Metadata está basado en Apache Atlas, también comentado anteriormente.
Toda la información, sea RAW o Normalizada va a parar a un Data Lake, que será el repositorio de la información para que los entornos de Big Data se puedan conectar y generen nueva información. La Pipeline tiene varias iteraciones seguramente debido a las necesidades de negocio pero, en realidad, el sistema parece ser el mismo que vuelve a analizar los datos, seguramente con unas nuevas reglas de negocio para, a la salida, entregar a los consumidores sólo aquellos datos releventas.
Realmente un caso de uso interesante ya que contempla el uso de varios sistemas como son:
- Apache Kafka
- Apache Flink
- Apache Atlas
- Data Lake
Si queréis tener más información sobre el caso presentado podéis ver la siguiente presentación de Bas Geerdink, IT Manager Fast Data Analytics at ING.
Visualización con Superset
Superset va a permitir explorar nuestros datos indexados en Druid como crear consultas JSON interactivas que luego podremos usar para dar empowerment a nuestros dashboards.
¿Qué usos podemos darle a Superset? Si estamos utilizando un CRM, como poníamos de ejemplo al inicio del post, podemos utilizar nuestra base de clientes para realizar informes, dashboard de control, etc… específicos para identificar cambios de tendencia en el uso de nuestro producto y/o servicio y comprender mejor el comportamiento del cliente. También, en caso que tenemos un equipo específico de Data Science, podría utilizarlo como BI avanzado para realizar análisis exploratorios de datos en relación con diferentes cohortes de usuarios antes de crear modelos de Machine Learning, etc…
