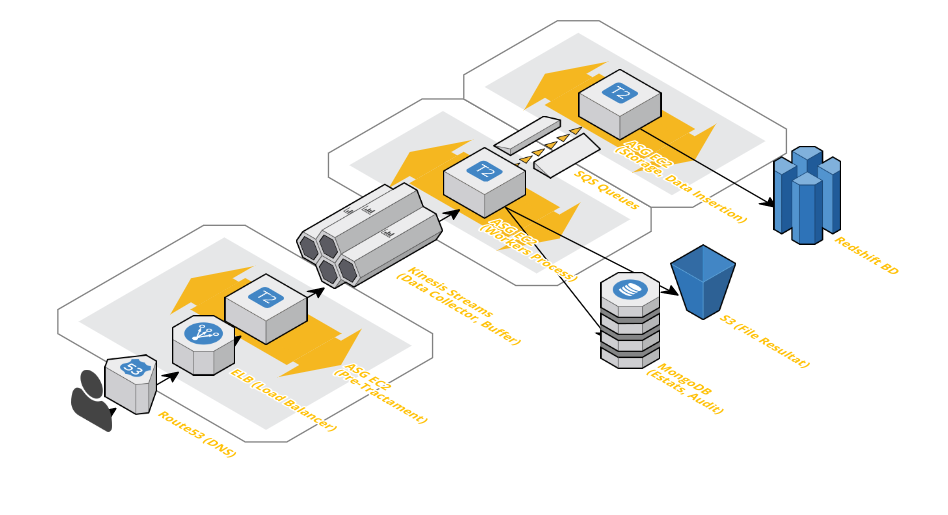
Si tenemos una necesidad de inserción masiva de datos, podemos disponer, a la vez, de varios Servicios de AWS como son: AWS Load Balancer, ASG EC2, AWS Kinesis Streams y AWS redshift ellos nos van a dar la poténcia necesaria para tener una más que correcta Pipeline de inserción, buffer y posterior filtrado y trato de los datos capturado.
Sin duda, esta Tipología de Arquitectura no es válida para cualquier tipo de inserción de datos, muchas veces los datos que se ingieren necesitan un Realtime que un proceso de Buffering no les puede dar. Para ello podemos optar a tener, previamente a el proceso de Data Collector, un sistema basado entre Load Balancers e instancias EC2 en autoescalado.
¿Qué buscamos?
Hay que pensar de entrada que el 100% de disponibilidad y servicio es muy difícil, pero no imposible, para ello pensaremos Arquitecturas que como mínimo la conjunción de todos sus componentes tengan un nivel de Servicio de 99,99%. Para ello podemos ayudarnos de servicios de AWS como S3 que disponen de niveles de servicio de 99,999999999%. Pero: ¿Qué haremos con tanta pieza tecnológica?. ¡Vayamos a verlo!.
Data Ingestion
El momento más preocupante es aquél que conecta con nuestros usuarios/clientes. El momento de la acción, el interés, la compra, etc… eso desencadena una Pipeline de ejecuciones que, la capa Load Balancer, tendrá que Pre-Tratar y devolver el resultado esperado para que en milisegundos (ms) nuestro cliente tenga la respuesta esperada.
No estamos hablando de webs de compras simples, estamos hablando de análisis de datos posteriores o segundas ejecuciones que tras ese Pre-Tratamiento deberán, luego, volver a ejecutar nuevas cadenas de proceso. Son sistemas muy complejos de datos.
Data Collector
Identificaremos éste proceso como aquél punto de conexión entre el dato “Realtime” y el dato que se procesará y nos dará nuevos datos y/o acciones posteriores no inmediatas.
Podemos usar AWS Kinesis Streams, por ejemplo o el también famoso Apacha Kafka. En este caso, usaremos Kinesis.
AWS Kinesis nos permitirá filtrar datos, analizar los paquetes de los mismos y, una parte muy importante, aplicar un Buffering de espera que nos permita tener en todo momento el control de la ejecución. A su salida, ya sea mediante un SQS (Queue System) o por AWS Firehouse, podremos mandarlo a aquella cola de tratamiento (workers) que nos interese. Realmente es un potencial enorme para una Pipeline que tratará tanto datos “Realtime” como diferidos.
Data Processing
Hay muchas y variantes formas de tratar los datos, pueden ser a la misma salida del Buffering o, tras un proceso de Queues (SQS), según nuestros interés podemos aplicar una u otra solución. Por ejemplo si introducimos AWS Firehouse, el SQS está embebido dentro de la operativa y nos “ahorraríamos” este segundo proceso. En nuestro caso, colocaremos un sistema ASG EC2 para, ya sea mediante lenguajes de alto nivel como Python o Spark, podamos tratar aquellos datos y guardarlos en una primera instancia (RAW), ya sea en una base de datos NoSQL como MongoDB o, directamente en un fichero JSON en S3 que luego podremos explotar a partir de procesos Spark que nos permitirán operar con uno o varios ficheros a la vez directamente indicando su Path en S3.
Éste es un paso para salvaguardar los datos RAW y tener un punto lo más cercano posible al Dato Real. Siempre nos puede ir bien, una vez finalizado el proceso de Pipeline, la comparativa entre el Dato Real y el Dato Final.
Data Consumer
No olvidemos que, por lo general, el dato RAW “no nos sirve”, tendremos que aplicar aquellos proceso de negocio que son, ya sea nuestro Valor Añadido o, simplemente, una necesidad. Para ello podemos volver a usar instancias EC2 en Autoescalado (ASG) para dotar de proceso de Alto Nivel y realizar la inserción del dato final en una base de datos mixta (SQL + NoSQL) como lo es AWS Redshift.
Éste paso no es un simple INSERT a la base de datos, es también un ejecución de reglas de negocio que nos van a permitir obtener aquellos datos que se requieran para nuestro correcto funcionamiento, para estadísticas y paneles de control, etc… para ello, utilizar AWS Redshift, puede ser una gran solución para nosotros ya que disponemos de muchos otros servicios como por ejemplo: AWS QuickSight.
Es muy fácil explicar la imagen pero no es tan fácil ni identificar la mejor de las soluciones a nuestra necesidad ni, por supuesto, montarlo. Este ha sido un breve artículo para exponer, sencillamente, una correcta solución para un proceso de ingestión masivo de datos. Se requiere mucho más análisis para determinar si sería una buena opción para vuestra necesidad.